Cada DLCI deve ser mapeado ao endereço de camada 3 de seu vizinho, processo que pode ser realizado manualmente ou dinamicamente utilizando-se o Inverse ARP. Portanto, em uma rede frame-relay cada conexão será identificada com um DLCI, o qual deve ter mapeado o endereço IP do dispositivo remoto para que os pacotes possam ser enviados até ele através de uma nuvem frame-relay através de um DLCI local. Por isso o nome ARP Inverso ou Inverse ARP, pois no ARP mapeamos um endereço IP remoto ao MAC remoto e aqui mapeamos um endereço de camada 2 local (DLCI local) ao endereço de camada 3 remoto.
A comunicação entre os dispositivos finais ou CPEs e a nuvem frame-relay se dá através de um protocolo local que roda entre o CPE e seu switch frame-relay chamado LMI, lembrando que normalmente esse parâmetro não precisa ser configurado para IOSs superiores à versão 11.3.
O frame-relay pode ser conectado em dois tipos de topologia: “partial mesh” (malha parcial) ou “full-meshed” (malha completa). A diferença entre uma rede full-meshed para uma partial meshed é que na primeira todos os PVCs possíveis devem ser criados entre os CPEs. Uma malha parcial muito utilizada na prática é a Hub and Spoke, representada na figura abaixo. Nessa rede temos um roteador central chamado de Hub e vários routers remotos chamados Spokes,
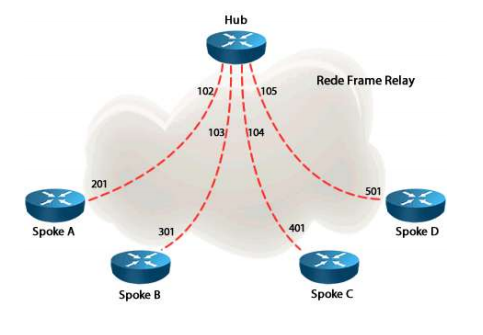
Em termos de vizinhança nessa topologia ela será estabelecida apenas entre o roteador Hub e cada um dos spokes, sendo que os spokes não estabelecerão vizinhanças entre si, pois para que haja esse estabelecimento seriam necessários PVCs criados entre eles. Portanto, em um “show ip eigrp neighbors” (tabela de vizinhança) o Hub terá como vizinho os spokes A, B, C e D, porém cada Spoke terá apenas o Hub em sua tabela. As topologias em malha completa não têm restrições com relação ao funcionamento ou estabelecimento de vizinhanças no EIGRP, pois haverão PVCs criados entre todos os CPEs.
É importante lembrar que para as topologias em malha parcial, especialmente Hub and Spoke, quando conectadas com interfaces ou subinterfaces multiponto essas ficam sujeitas ao Split Horizon. Na prática ocorre que o Hub irá conhecer as redes dos spokes, porém os spokes conhecerão apenas as redes do Hub, pois a rede dos vizinhos spokes será bloqueada pelo split horizon. Por exemplo, quando o spoke A anuncia suas redes ao Hub ele não poderá retransmitir esse mesmo anúncio para os DLCIs 103, 104 e 105, pois em uma rede NBMA todos os DLCIs estariam na mesma interface, subinterface e consequentemente na mesma rede ou sub-rede IP, portanto o split horizon não permitirá o encaminhamento do anúncio na mesma interface. Para resolver esse problema podemos utilizar subinterfaces ponto a ponto ou então desativar o split horizon no roteador Hub.
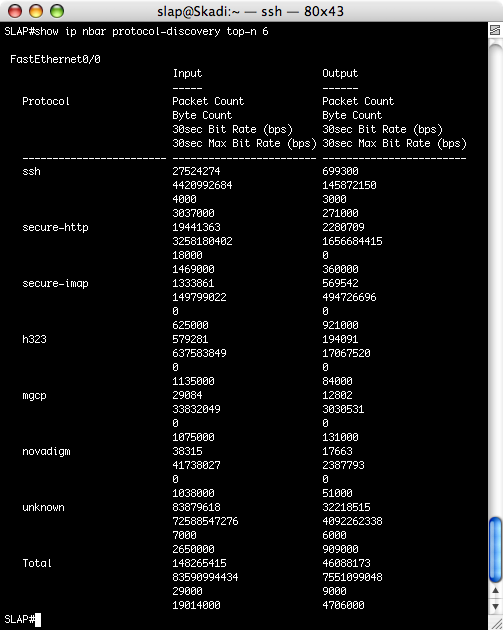
Analise a topologia da figura abaixo onde as interfaces estão configuradas com o frame-relay padrão nas interfaces físicas e R1 é o roteador HUB com DLCIs apontando para R2 e R3 conforme tabela de encaminhamento do switch frame-relay FR1.

Se nenhuma configuração extra for realizada os roteadores R2 e R3 apenas visualizarão suas
próprias redes e a rede de R1 e não conseguirão visualizar em suas tabelas de roteamento as
redes um do outro. Veja exemplo do show ip route no roteador R2 abaixo e note que a rota
para R3 está faltando:

Agora vamos desativar o split horizon em R1 para que as rotas possam ser aprendidas por R2 e
R3 com o comando dentro da interface serial 0/0 “no ip split-horizon eigrp 100"

Note que após o comando imediatamente o EIGRP faz uma resincronização (resync) passando
as redes para os vizinhos R2 (192.168.1.2) e R3 (192.168.1.3). Após esse comando veja o que
acontece em R2. Primeiro o EIGRP avisa um resincronismo e um “gracefull restart”, ou seja, a
vizinhança está sendo reinicializada. Após isso com o show ip route já conseguiremos visualizar
a rede de R3 10.0.2.0 na tabela de roteamento.

Lembre-se que a configuração padrão do frame-relay nas interfaces Cisco faz com que todas as
interfaces estejam na mesma sub-rede, chamada de rede NBMA ou Non-broadcast Multiple
Access Network. Aqui nesse detalhe é onde na prática devemos tomar cuidado na escolha de
que opção devemos utilizar para a configuração das interfaces frame-relay, pois ela pode ser: